




FRM考试作为金融类的考试,里面涉及到数学的一些基础知识。其中主要就是概率与统计的内容,在本篇文章中,小编就请来咱们的FRM老师为大家讲解FRM数学基础中的有关统计学的知识。
样本变异量是基本统计学一个很难懂也很难教的概念。初学统计学的学生一开始就遇到这个概念,如果没学懂,很可能就对统计学丧失了信心或兴趣。这个概念难懂之处并不只在于它的意义或用处,更在于它的公式:
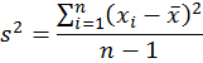
变异量的概念
首先,我们假设给有一组n个数目的数据:X1,X2,X3.......Xn, 他们的样本平均数是X。
变异量所要测量的是这一组数据彼此间差异的程度,它告诉我们数据的同构型或一致性。我们可以先想象这组数据全部相同的情况:数据彼此之间完全没有差异,也就是同构型高到不能再高了,一致性也大到不能再大了,此时变异量为0。如果数据彼此间差异*大,也就是同构型或一致性*低,此时变异量*大。
然则为何变异量要用上面的公式计算?要算数据彼此间差异的程度,不是算出数目两两之间差异的总和或其平均值就好了吗?这样说虽然不无道理,但实际上大有问题。
设想我们把数据中所有数目依其大小标在一直在线,一共有n个点,则这些点两两之间一共会有C(n,2)=n!/(n-2)!2!个距离,例如n=3会有3个距离,n=4会有6个距离,n=5会有10个距离,等等。但这些距离并不是相互独立的,因为除了相邻两点之间的距离外,其它的距离都可以算出来。举例来说,若n=3而三点为x1
如果我们把总变异量定义为数据中这些独立信息的总和,则当我们把总变异量除以自由度n-1,我们就得到这些独立信息的平均变异量了。但这样的定义有一个问题,我们看下式就明白了:
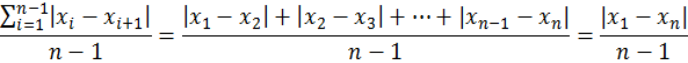
这就等于我们小学时学过的植树问题:「一条路有90公尺,沿路每边种了10棵树,两端都种,请问每边树与树间的平均距离多少?」这样来算变异量,除了用到数据*数和*小数之间的「范围」(range) 外,完全忽略了中间n-2个相对点位置所含的信息,因此它不是一个适当的方法。
此外,因为两数相减可能得到负数,但距离必须是正的,所以我们常用*值来算距离。但*值函数y=|x|在x=0的地方有个尖锐转折,不是一个平滑函数,数学上不好处理。比较好的消去负号的方法是平方:负负得正。
因此统计学不用数据点两两之间距离*值的和来算总变异量,而是用每个数据点与平均数距离平方的总和,也就是前面所说的「差方和」。差方和的好处是它用到了数据中每一点的位置,但它同时也必须用到样本平均数。用了样本平均数之后,数据中的n个点与平均数的距离就有一个限制了。
因此它们只包含了n-1个独立的信息。我们把n-1唤作「自由度」,也就是独立信息的数目。把差方和除以「自由度」就得到变异量;它可以诠释为每个独立信息对数据所含总信息——差方和——的平均贡献。变异量因为用了距离的平方,必须开根号才能回到原来的距离单位。于是我们把变异量开根号,得到的结果,就是所谓「标准偏差」(standard deviation):
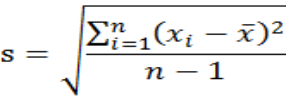
这里讲解的FRM数学基础知识主要是回答一个问题,即统计学中自由度修正为啥n-1?融跃FRM老师针对这个问题做了详细解答,如果有什么疑惑,欢迎留言咨询咱们的老师。
- 报考条件
- 报名时间
- 报名费用
- 考试科目
- 考试时间
-
GARP对于FRM报考条件的规定:
What qualifications do I need to register for the FRM Program?
There are no educational or professional prerequisites needed toregister.
翻译为:报名FRM考试没有任何学历或专业的先决条件。
可以理解为,报名FRM考试没有任何的学历和专业的要求,只要是你想考,都可以报名的。查看完整内容 -
2024年5月FRM考试报名时间为:
早鸟价报名阶段:2023年12月1日-2024年1月31日。
标准价报名阶段:2024年2月1日-2024年3月31日。2024年8月FRM考试报名时间为:
早鸟价报名阶段:2024年3月1日-2024年4月30日。
标准价报名阶段:2024年5月1日-2024年6月30日。2024年11月FRM考试报名时间为:
早鸟价报名时间:2024年5月1日-2024年7月31日。
标准价报名时间:2024年8月1日-2024年9月30日。查看完整内容 -
2023年GARP协会对FRM的各级考试报名的费用作出了修改:将原先早报阶段考试费从$550上涨至$600,标准阶段考试费从$750上涨至$800。费用分为:
注册费:$ 400 USD;
考试费:$ 600 USD(第一阶段)or $ 800 USD(第二阶段);
场地费:$ 40 USD(大陆考生每次参加FRM考试都需缴纳场地费);
数据费:$ 10 USD(只收取一次);
首次注册的考生费用为(注册费 + 考试费 + 场地费 + 数据费)= $1050 or $1250 USD。
非首次注册的考生费用为(考试费 + 场地费) = $640 or $840 USD。查看完整内容 -
FRM考试共两级,FRM一级四门科目,FRM二级六门科目;具体科目及占比如下:
FRM一级(共四门科目)
1、Foundations of Risk Management风险管理基础(大约占20%)
2、Quantitative Analysis数量分析(大约占20%)
3、Valuation and Risk Models估值与风险建模(大约占30%)
4、Financial Markets and Products金融市场与金融产品(大约占30%)
FRM二级(共六门科目)
1、Market Risk Measurement and Management市场风险管理与测量(大约占20%)
2、Credit Risk Measurement and Management信用风险管理与测量(大约占20%)
3、Operational and Integrated Risk Management操作及综合风险管理(大约占20%)
4、Liquidity and Treasury Risk Measurement and Management 流动性风险管理(大约占15%)
5、Risk Management and Investment Management投资风险管理(大约占15%)
6、Current Issues in Financial Markets金融市场前沿话题(大约占10%)查看完整内容 -
2024年FRM考试时间安排如下:
FRM一级考试:
2024年5月4日-5月17日;
2024年8月3日(周六)上午;
2024年11月2日-11月15日。FRM二级考试:
2024年5月18日-5月24日;
2024年8月3月(周六)下午;
2024年11月16日-11月22日。查看完整内容
-
中文名
金融风险管理师
-
持证人数
25000(中国)
-
外文名
FRM(Financial Risk Manager)
-
考试等级
FRM考试共分为两级考试
-
考试时间
5月、8月、11月
-
报名时间
5月考试(12月1日-3月31日)
8月考试(3月1日-6月30日)
11月考试(5月1日-9月30日)

