


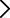


来自:FRM > 一级 > 数量分析 2023-03-17 19:41
老师,用铅笔标出来这里,有点分不清
 查看更多
查看更多
辞九
提问
26
上次登录
1096天前

 查看更多
查看更多
辞九
提问
26
上次登录
1096天前

Jason 2023-03-19 18:55
致精进的你:
所谓样本均值的标准差,实际上就是标准误。如果总体的标准差知道,可以用第一个公式求,但是通常,总体的标准差我们是未知的,这个时候如果还要求标准误,我们可以先求出来样本的方差,然后利用点估计的思想,我们用样本的方差代替总体的方差,去计算最终的标准误。 1.65×σ,1.65代表的是关键值,σ代表标准差,二者结合代表偏离均值的水平
The real talent is resolute aspirations.
真正的才智是刚毅的志向。
追问12023-03-20 21:21
老师您好,在1.65*σ这里,不应该是在计算置信区间,使用标准误吗?为什么这里是用标准差,或者网课老师举例时不是在计算置信区间

回答2023-03-21 16:34
定量分析这门课不是我讲的,所以我太不清楚授课老师在这个部分是怎么介绍的,但是呢,我可以给你稍微的明确一下标准差和标准误的概念,然后你再思考一下。 所谓的标准差,我再上次回复的时候已经提到了,它衡量的就是偏离均值的水平,衡量的是一种离散程度。具体并且准确的说,可以把它理解为,衡量总体中,每个个体之间的离散程度。 标准误是样本均值的标准差,那什么叫样本均值的标准差呢,他指的其实就是,我们首先在一个总体当中进行抽样,然后,对于抽出的样本的离散程度,我们用标准误来衡量。 定义搞清楚以后,再比较一下他们的用途。刚才通过定义,你应该能够明确,标准差用于衡量总体中每个个体的离散程度,标准误用于衡量样本中每个成分的离散程度,再结合推断统计和描述性统计的特征,是不是可以得到一个结论, 标准差用于描述性统计,然而标准误用于推断统计。好,那现在,我们来区分一下他们的用途,如果总体的情况你不知道,直接做描述性统计肯定就不现实了,因为总体情况未知,你没办法直接计算总体均值,总体方差,总体标准差等等,这个时候你会选择通过抽样,通过对样本的描述,来进行推断统计,从而获取这个总体的情况。那在推断统计当中,你是不是希望算出来的标准误越接近标准差越好。因为标准误是样本的特征,标准差是总体的特征,如果你的样本能完全代表总体,那证明推断统计的结果就是完全正确的吧。所以,标准误和标准差之间的区别,我们是不是可以理解为是一种抽样误差。 那现在我们回到置信区间的计算里面,理论上,我们应该用标准差来进行计算吧,因为标准差才是总体最真实的特征,但是,总体的标准差大多数情况下我们是不知道的,所以,如果你想估计置信区间,就要用标准误。那在应用当中呢,比如计算VaR的时候,我们用的就是标准差,但是,在统计学当中,我们更加严谨的考虑了总体和样本的差异,所以,在定量分析当中,我们更多的表达为标准误。




